CQRS (Command Query Responsibility Segregation) pattern is a simple pattern but is often misunderstood. At least for me, this pattern was quite scary at the beginning, while in fact, it’s quite simple and useful. In this guide, I will explain what it is, how it works, and implement demo project using CQRS/DDD principles. For this, I will be using .NET Core stack, MSSQL database. Demo code is available on my github (https://github.com/bolicd/practicalcqrs) and should be properly documented to get you started.
What is CQRS?
CQRS is an architectural pattern that separates read and write operations. This allows the application to scale better and perform well under a heavy load. Fundamentally, it is an implementation of the single responsibility principle (SRP) applied to the domain model layer.
It is useful for solving the issue of impedance mismatch — misalignment of database model and domain model.
There are no frameworks or tools that should be used, CQRS simply states that the domain write model and read model should be separated.
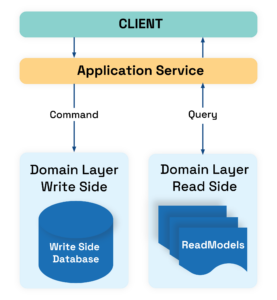
A simple diagram that shows the most important aspects of the CQRS:
Application service handles commands or query depending on the write or read side. For write, we use a command that returns no result. For read, we use a query that has no side effects and returns a result:
- Commands (Write side) — are used to “tell” write side to do something.
Commands perform action which has side-effect and return no result. For example: Change dossier status to active — this is a command which should be invoked from UI as a task. Therefore, we usually have Task based UI on the frontend.
Commands can be processed both asynchronously(eg. queue) and synchronously. - Query (Read side) — are used to fetch data from the read side. Queries always return result and can’t mutate state or have side effects. Therefore, query is something like: Get all active dossiers.
- Write and read sides are separated. This can be done via separate tables, databases, etc.
- Read side can implement denormalized materialized views or NoSQL table, write side can implement an event store or simple table, depending on scaling needs.
CAP Theorem and CQRS trade-offs
CAP theorem states that, for a distributed data store, it is impossible to achieve more than two of the following:
- Consistency — Every read receives the most recent write or an error
- Availability — Every request receives a (non-error) response, without the guarantee that it contains the most recent write
- Partition tolerance — The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes
Depending on what needs to be scaled in CQRS system, Consistency or Availability can be sacrificed (or both) to achieve better scalability.
It is important for both business users as well as developers/architects to understand that CQRS will have trade-offs that can affect user experience.
Scaling read side in CQRS
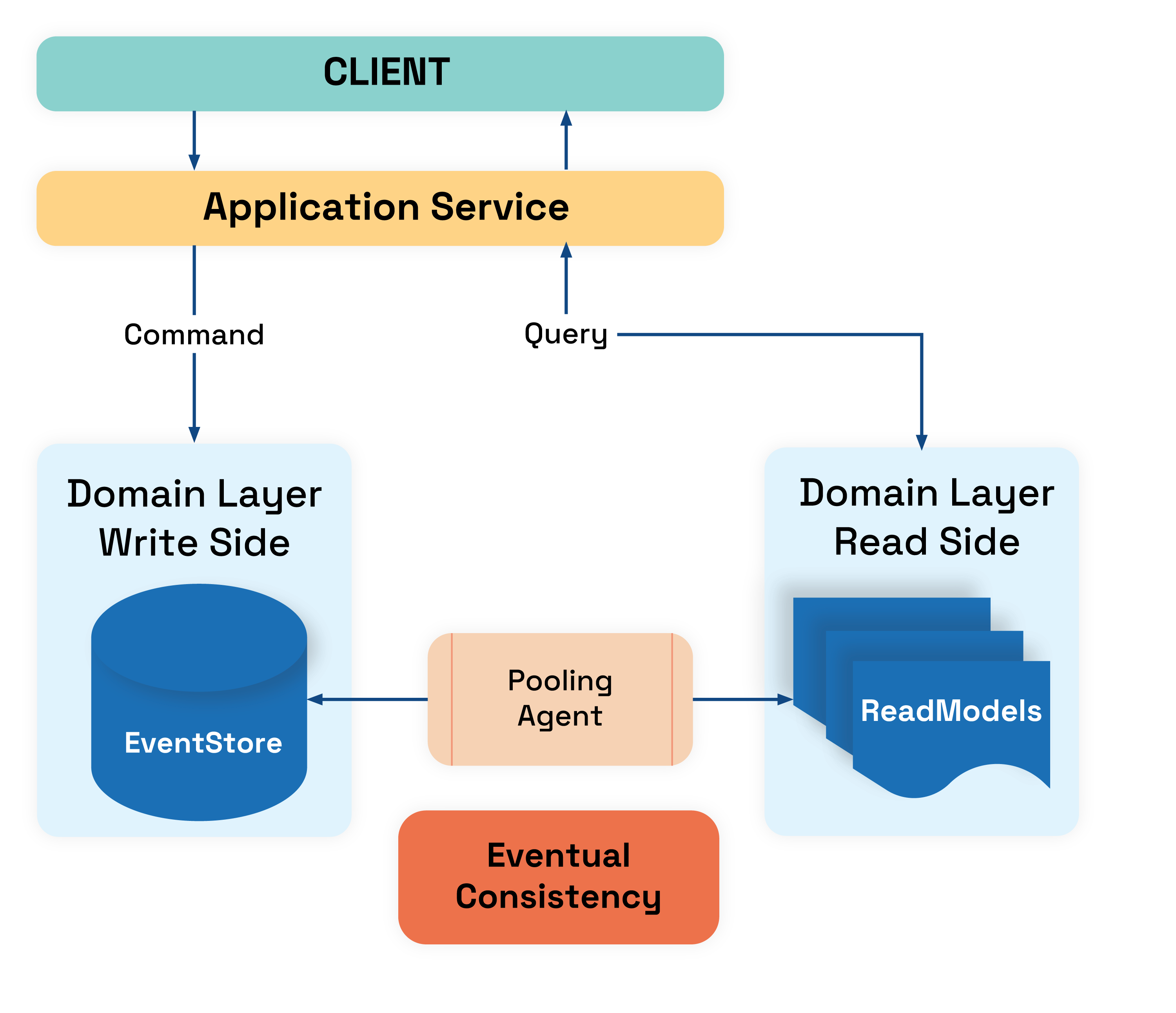
Scaling the read side means introducing eventual consistency. In practice, this is usually done by creating denormalized read models which are populated from the write side. This can be done using:
- Pooling agent — is a service which pools event store (ES) for changes. If new events are detected all subscribing projections(read models) are updated. We consider this a pull model.
- Queue — we can use publish/subscriber pattern using queue (like service bus) where our projections subscribe to certain events. Events are published as soon as they arrive in write model. In this case, everything is handled by the queue and we consider this a push model.
Pooling agent can give more control, and guarantees at most once delivery in order. However, it requires it to be single threaded service that runs on one machine at a time (due to the fact that it needs to read and send events in order). This means that it is less scalable.
Queue is usually implemented using some off the shelf queue but we have less control over events distribution and more
Scaling write side
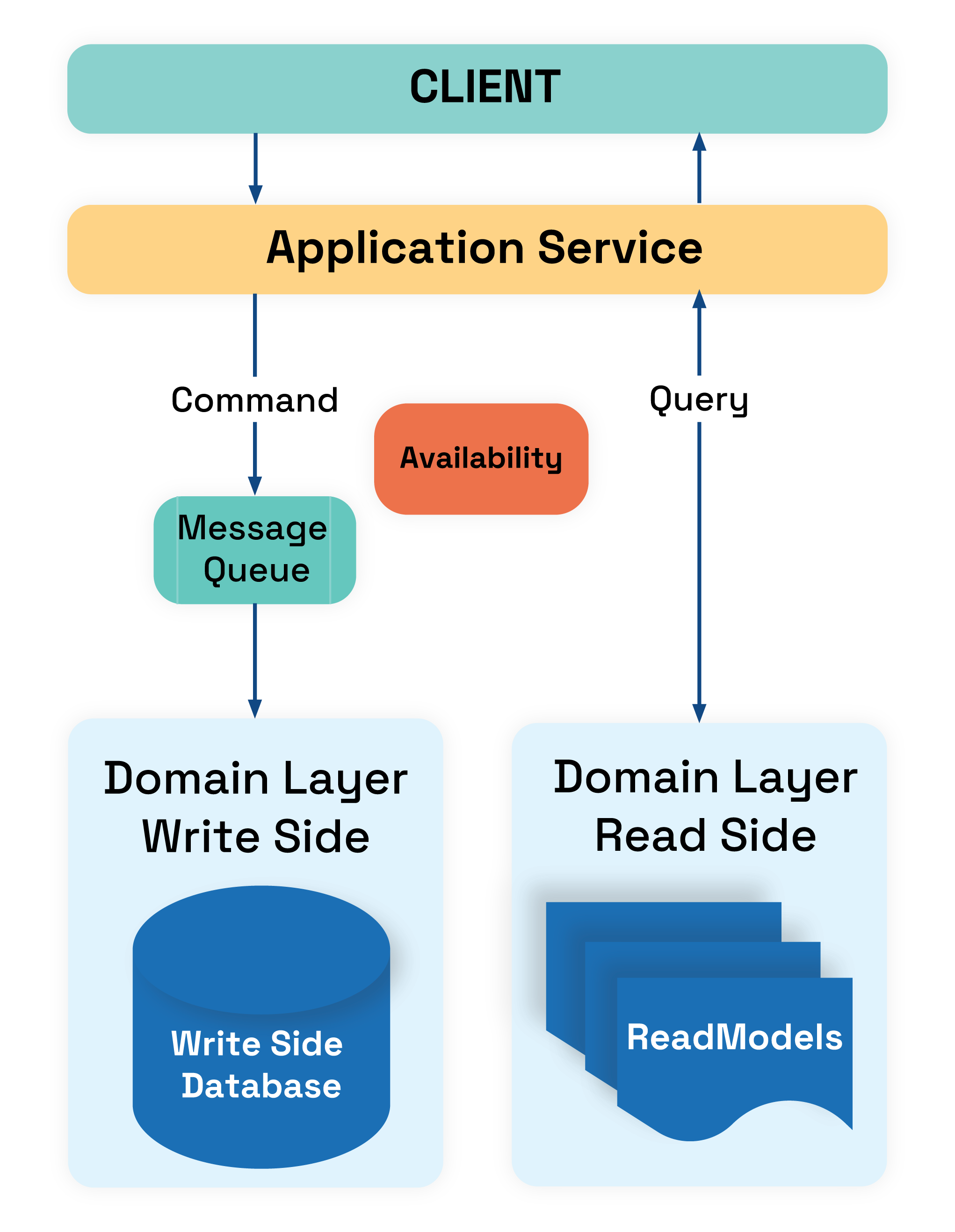
If amount of requests coming from clients is high, write side can be scaled using Message Queue — commands are sent to the queue and client get the immediate response back. There are couple of things that business user needs to be aware in this scenario:
-
- Acknowledge from a command
doesn’t mean that the command is processed
-
- , it means that the command is saved into queue: An example of this would be when buying on amazon we buy something- a command is issued, validated and response is sent back. The item becomes sold, but the actual transaction to deduct amount of money is executed later on.
Command should be validated as best it can before it is placed on the queue, to minimize the chance of error later on when processing.
This way we increase scalability at a loss of availability.
When to use CQRS and when to avoid
In general, when we have rich/complex business logic CQRS is a good pattern to use.
It can provide limitless scalability for both the read and write side but with some trade-offs, like event consistency, which need to be clearly communicated to the business user.
CQRS can be built without Event Sourcing, asynchronous messaging, or eventual consistency.
Practical CQRS Example Project
I’ve created a small project to demonstrate most of the basic principles laid out in this article: https://github.com/bolicd/practicalcqrs is built upon my already existing project for event store (found here: https://github.com/bolicd/eventstore) but also adds more DDD principles:
Example of CQRS separations for both read and write side.
Write side uses simple event store
Read side uses projection agents which pool event store and populate read models as needed. This introduces eventual consistency.
The purpose of this project was NOT clear architecture so it should not be considered as such. Mostly everything in this project is implemented by hand so that the source code can be easily understood (as opposed to using pre existing library for example).
Pooling agent is implemented as Projections, where each projection can react to certain events from the event store and populate the corresponding read model.
I do hope that this will help someone better understand DDD and apply them.