
Implementing Repository pattern in Dapper can be done in many ways. In this blog I will explain what repository pattern is and how to implement it using reflection in C#. When searching around the web I found various implementations none of which was satisfactory — mostly due to having to manually enter table names/field names, too complex implementations with Unit of work etc. Similar repository, as presented here, is in use in production CQRS/ES system and works quite well. Even though use case depicted here is quite “unique”, I think implementation of this repository can be applied for most of the relational base database systems, with minimum refactoring.
What is Repository pattern?
When talking about Repository pattern it is important to distinguish between DDD implementation of repository and generic repositorypattern.
Generic repository is simple contract defined as an interface on per object basis. That means that one repository object is related to one table in database.
DDD repository pattern works with aggregate root object and persists it one or more tables or if event sourcing is used as series of events in event store. So in this instance, repository is actually related not to one database but to one aggregate root which can map to one or more tables. This is a complex process due to impedance mismatch effect which better handled with ORM’s, but this is not our use case.
Generic repository UML diagram:
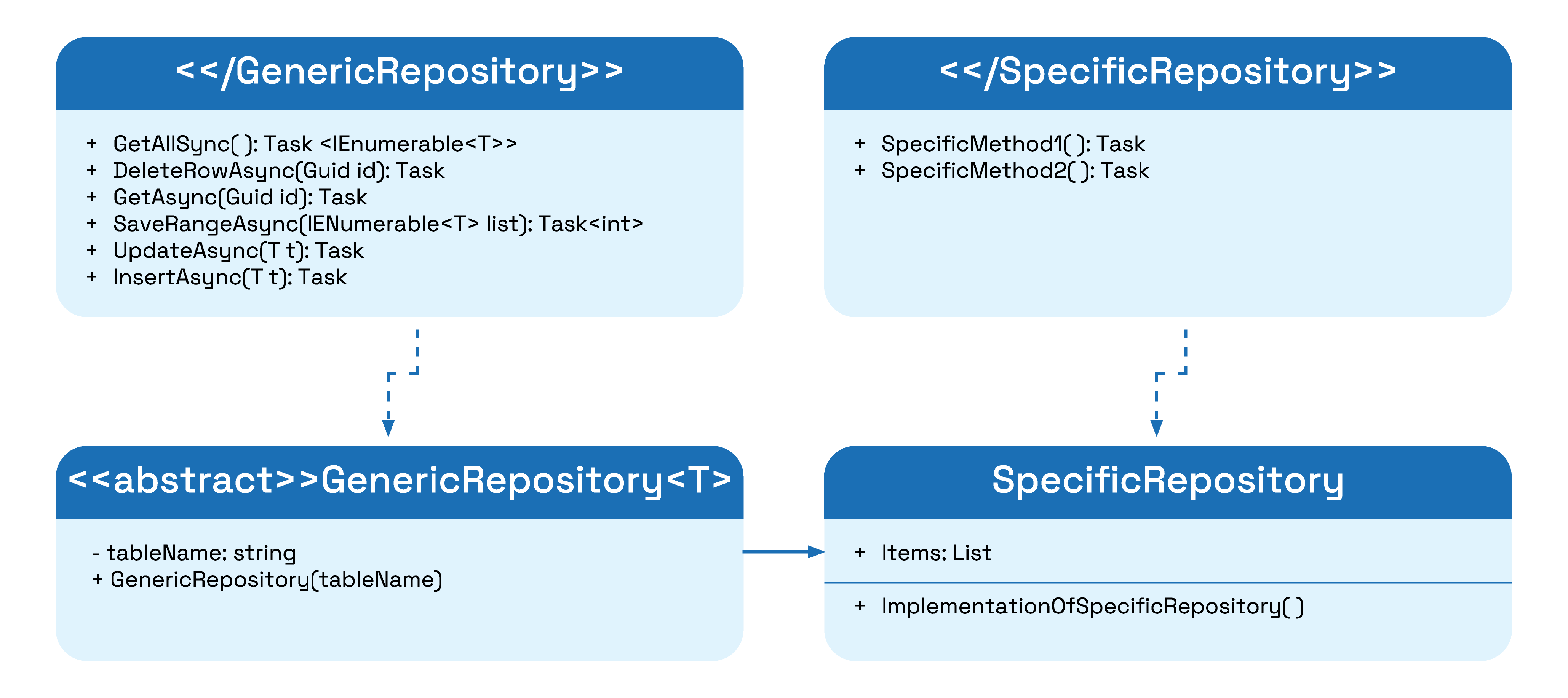
- GenericRepository abstract class implements IGenericRepository interface. All shared functionality is implemented in this class.
- ISpecificRepository interface should have methods required for specific use case (if any)
- SpecificRepository class inherits from GenericRepository abstract class and implements any specific methods from ISpecificRepository.
Unit Of Work and transaction handling
Unit of Work pattern implements single transaction for multiple repository objects, making sure that all INSERT/UPDATE/DELETE statements are executed in order and atomically.
I will not be using Unit Of Work but rather save each repository directly using Update/Insert method. The reason for this is that these repositories are designed toward a specific use case detailed below.
All transaction handling is done manually by wrapping multiple repository command into .NET Transaction object. This gives a lot more flexibility without adding additional complexity.
Repository implementation
Let us define the interface first:
public interface IGenericRepository
{
Task GetAllAsync();
Task DeleteRowAsync(Guid id);
Task GetAsync(Guid id);
Task SaveRangeAsync(IEnumerable list);
Task UpdateAsync(T t);
Task InsertAsync(T t);
}Bootstrap code for repository class has the responsibility to create SqlConnection object and open the connection to database. After that, Dapper will utilize this connection to execute SQL queries against database.
public abstract class GenericRepository : IGenericRepository where T: class
{
private readonly string _tableName;
proteted GenericRepository(string tableName)
{
_tableName = tableName;
}
/// <summary>
/// Generate new connection based on connection string
/// </summary>
///
private SqlConnection SqlConnection()
{
return new SqlConnection(ConfigurationManager.ConnectionStrings["MainDb"].ConnectionString);
}
/// <summary>
/// Open new connection and return it for use
/// </summary>
///
private IDbConnection CreateConnection()
{
var conn = SqlConnection();
conn.Open();
return conn;
}
private IEnumerable GetProperties => typeof(T).GetProperties();connectionString="Data Source=(localdb)\mssqllocaldb;Integrated Security=true;Initial Catalog=dapper-examples;"
providerName="System.Data.SqlClient"/>Implementing most of these methods, except for Insert and Update, are quite straightforward using Dapper.
public async Task<IEnumerable> GetAllAsync()
{
using (var connection = CreateConnection())
{
return await connection.QueryAsync($"SELECT * FROM {_tableName}");
}
}
public async Task DeleteRowAsync(Guid id)
{
using (var connection = CreateConnection())
{
await connection.ExecuteAsync($"DELETE FROM {_tableName} WHERE Id=@Id", new { Id = id });
}
}
public async Task GetAsync(Guid id)
{
using (var connection = CreateConnection())
{
var result = await connection.QuerySingleOrDefaultAsync($"SELECT * FROM {_tableName} WHERE Id=@Id", new { Id = id });
if (result == null)
throw new KeyNotFoundException($"{_tableName} with id [{id}] could not be found.");
return result;
}
}
public async Task SaveRangeAsync(IEnumerable list)
{
var inserted = 0;
var query = GenerateInsertQuery();
using (var connection = CreateConnection())
{
inserted += await connection.ExecuteAsync(query, list);
}
return inserted;
}For SaveRangeAsync list of items is provided which are saved to database and returns number of items saved. This can be made atomic by wrapping foreach in Transaction object.
Implementing Insert and Update queries
Implementing insert and update requires a bit more work. In general idea is to use reflection and extract field names from model class and then generate insert/update query based on field names. Field names will be used as parameter names for Dapper therefore it is important to make sure that DAO class field names are the same as column names in actual table.
In both cases the idea is the same: take object, provided as input parameter, and generate SQL query string with parameters. The only change is that different query is generated, INSERT or UPDATE.
Both methods use reflection to extract field names from model object. This class can be made static, since its not using any of instance variables and for performance purposes.
private static List GenerateListOfProperties(IEnumerable listOfProperties)
{
return (from prop in listOfProperties let attributes = prop.GetCustomAttributes(typeof(DescriptionAttribute), false)
where attributes.Length <= 0 || (attributes[0] as DescriptionAttribute)?.Description != "ignore" select prop.Name).ToList();
}What this does is extracts a list of attribute names into List using reflection. It will not extract fields marked with ignore description attribute.
Once we have this list we can iterate it and generate actual query:
public async Task InsertAsync(T t)
{
var insertQuery = GenerateInsertQuery();
using (var connection = CreateConnection())
{
await connection.ExecuteAsync(insertQuery, t);
}
}
private string GenerateInsertQuery()
{
var insertQuery = new StringBuilder($"INSERT INTO {_tableName} ");
insertQuery.Append("(");
var properties = GenerateListOfProperties(GetProperties);
properties.ForEach(prop => { insertQuery.Append($"[{prop}],"); });
insertQuery
.Remove(insertQuery.Length - 1, 1)
.Append(") VALUES (");
properties.ForEach(prop => { insertQuery.Append($"@{prop},"); });
insertQuery
.Remove(insertQuery.Length - 1, 1)
.Append(")");
return insertQuery.ToString();
}The update method has some small differences:
public async Task UpdateAsync(T t)
{
var updateQuery = GenerateUpdateQuery();
using (var connection = CreateConnection())
{
await connection.ExecuteAsync(updateQuery, t);
}
}
private string GenerateUpdateQuery()
{
var updateQuery = new StringBuilder($"UPDATE {_tableName} SET ");
var properties = GenerateListOfProperties(GetProperties);
properties.ForEach(property =>
{
if (!property.Equals("Id"))
{
updateQuery.Append($"{property}=@{property},");
}
});
updateQuery.Remove(updateQuery.Length - 1, 1); //remove last comma
updateQuery.Append(" WHERE Id=@Id");
return updateQuery.ToString();
}An additional thing we need to take care of here is what happens if record for updating is not found. There are couple of solutions for this, some include throwing an exception others returning empty object or somehow notifying calling code that update was not done.
In this case we are relying on Dappers executeAsync method which return int which is a number of affected rows.
Example of generic repository usage:
public static async Task Main(string[] args)
{
var userRepository = new UserRepository("Users");
Console.WriteLine(" Save into table users ");
var guid = Guid.NewGuid();
await userRepository.InsertAsync(new User()
{
FirstName = "Test2",
Id = guid,
LastName = "LastName2"
});
await userRepository.UpdateAsync(new User()
{
FirstName = "Test3",
Id = guid,
LastName = "LastName3"
});
List users = new List();
for (var i = 0; i < 100000; i++)
{
var id = Guid.NewGuid();
users.Add(new User
{
Id = id,
LastName = "aaa",
FirstName = "bbb"
});
}
var stopwatch = new Stopwatch();
stopwatch.Start();
Console.WriteLine($"Inserted {await userRepository.SaveRangeAsync(users)}");
stopwatch.Stop();
var elapsed_time = stopwatch.ElapsedMilliseconds;
Console.WriteLine($"Elapsed time {elapsed_time} ms");
Console.ReadLine();
}Use case in CQRS/ES Architecture
CQRS stands for Command Query Responsibility Segregation, and is an architectural pattern, which separates read model from write model. Theis to have two models which can scale independently and are optimized for either read or write.
Event Sourcing(ES) is a pattern which states that state of the object is persisted into database as list of events and can be later reconstructed to the latest state by applying these events in order.
I will not go into explaining what these two patterns are and how to implement them, but rather focus on specific use case I’ve dealt with in one of my projects: How to use relational database (MSSQL) for read model and event store, utilizing data mapper Dapper and Generic repository pattern. I will also touch, albeit briefly, event sourcing using the same generic repository.
Example architecture:
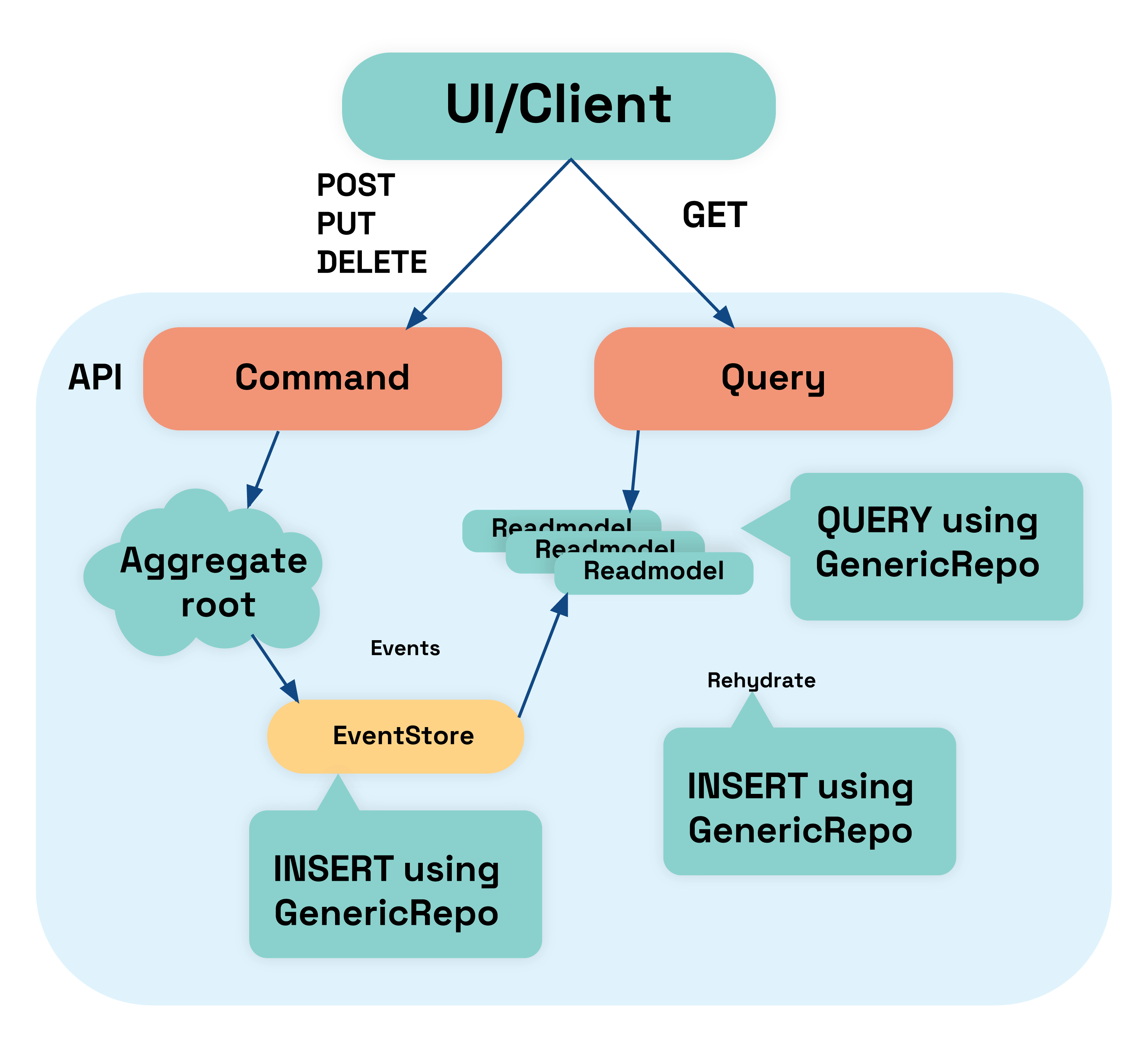
Before going any further let us consider why using data mapper would be more beneficial than using ORM for this particular case
Impedance Mismatch in Event Sourcing
An object-relational impedance mismatch refers to a range of problems representing data from relational databases in object-oriented programming languages.
Impedance mismatch has a large cost associated. Reason for this is that developer has to know both relational model as well as object oriented model. Object Relational Mappers(ORMs) are used to mitigate this issue but not eliminate it. They also tend to introduce new problems: like virtual properties requirement by EF, private properties mapping issue, polluting domain model etc.
When using using Events as storage mechanism in Event Store, there is no impedance mismatch! The reason for this is that events are domain concept and are persisted directly in Event store without any need for object relational mapping. Therefore, need for using ORM is minimal, and using Dapper/Generic repository becomes more practical.
Database model considerations
In this use case MSSQL will be used for both write and read sides, which adds to re-usability for dapper repository since it can be used on both read and write sides.
Primary key consideration
In this example I used Guid(.NET Guid and uniqueidentifier MSSQL datatype) as primary key It could have been something else like long or int, or string.
In any case this would require some additional work on Dapper repository. First, interface would need to change to accept additional primary key type. Then, depending on the type, there might be some additional work to modify queries generated.
Having more than one column as primary key would also imply some additional work and in this case using dapper/generic repository pattern would probably counter productive. We should opt for using full blown ORM in this case!
Bulk inserts with Dapper
Dapper is NOT suitable for bulk inserts, ie. performing large number of INSERT statements. The reason is that ExecuteAsync method, internally will use foreach loop to generate insert statements and execute them. For large number of records this is not optimal, and I would recommend using either SQL Bulk copy(link) functionality or Dapper extension which allows bulk copy(its commercial extension) or simply bypassing dapper and working with database directly.
Transactions handling
Use case for applying transaction is when saving into more than one table atomically. Saving into event store can be this example: save into AggregateRoot table and Events table as one transaction.
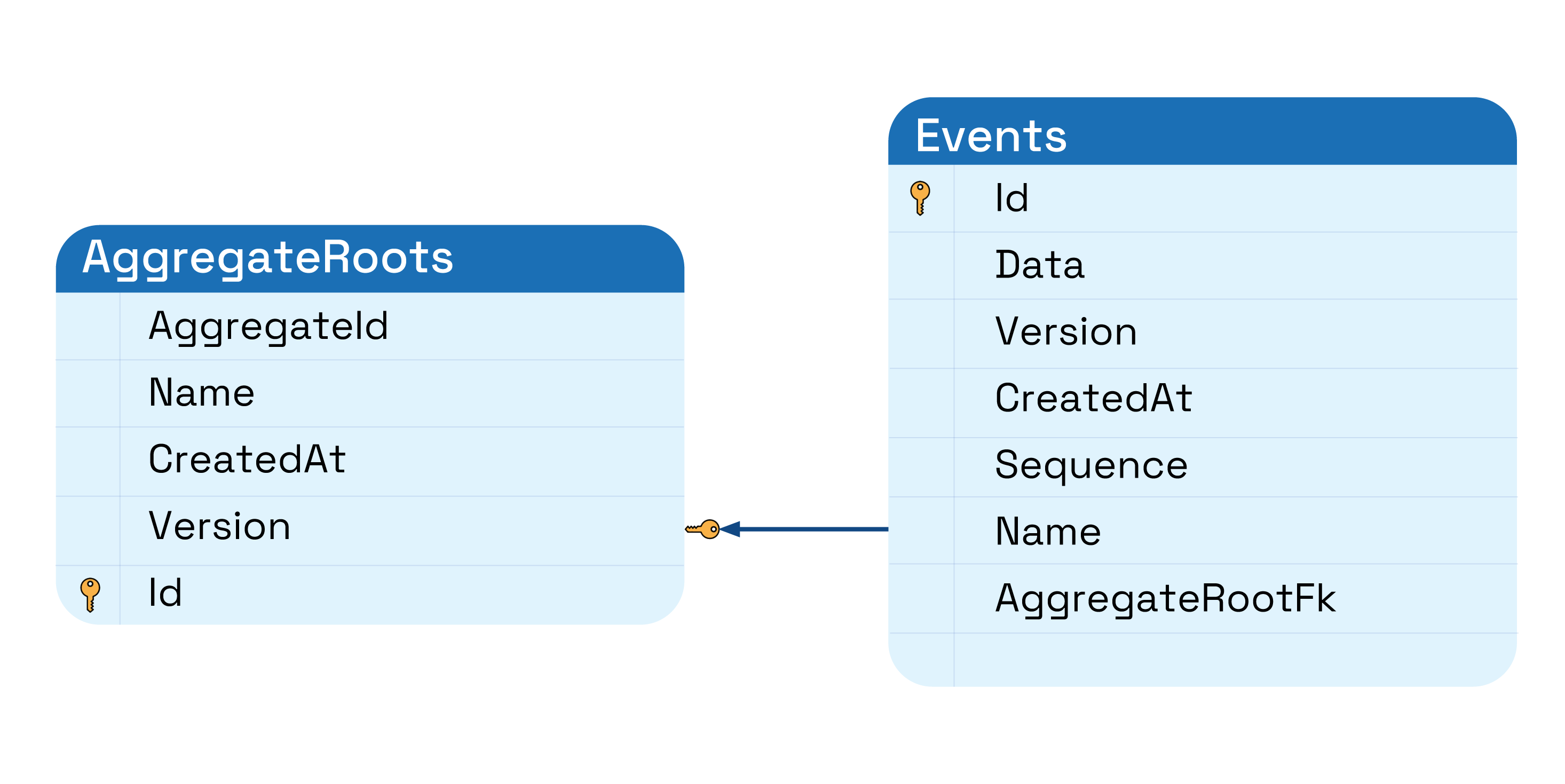
Transactions should be controlled manually either on Command level(in CQRS Command implementation) or inside repository.
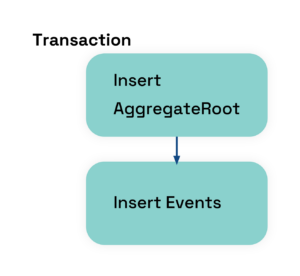
This example with two tables is inspired by Greg Young’s design which can be found here
using (var transaction = new TransactionScope(TransactionScopeAsyncFlowOption.Enabled))
{
// Fetch Aggregate root if exists, create new otherwise
var aggRoot = await _aggregateRootRepository.FindById(aggregateId.Identity);
if (aggRoot == null)
{
aggRoot = new AggregateRootDao
{
Id = Guid.NewGuid(),
CreatedAt = DateTime.Now,
AggregateId = aggregateId.Identity,
Version = 0,
Name = "AggregateName"
};
await _aggregateRootRepository.InsertAsync(aggRoot);
}
else
{
if (originatingVersion != aggRoot.Version)
throw new EventStoreConcurrencyException($"Failed concurrency check for aggregate. Incoming version: {originatingVersion} Current version: {aggRoot.Version}");
}
// Optimistic concurrency check
var domainEvents = events as IDomainEvent[] ?? events.ToArray();
foreach (var e in domainEvents)
{
// Increment Aggregate version for each event
aggRoot.Version++;
e.Version = aggRoot.Version;
// Store each event with incremented Aggregate version
var eventForRoot = new EventDao()
{
CreatedAt = e.CreatedAt,
AggregateRootFk = aggRoot.Id,
Data = JsonConvert.SerializeObject(e, Formatting.Indented, _jsonSerializerSettings),
Version = aggRoot.Version,
Name = e.GetType().Name,
Id = e.Id,
};
await _eventsRepository.InsertAsync(eventForRoot);
}
// Update the Aggregate
await _aggregateRootRepository.UpdateAggregateVersion(aggRoot.Id, aggRoot.Version);
transaction.Complete();
}If aggregate root is not found, it is created and inserted in AggregateRoot table. After that each event is converted to domain event and saved into Events table. All this is wrapped in transaction and will either fail or succeed as an atomic operation. Note that transaction has TransactionScopeAsyncFlowOption.Enabled option, which allows transaction to invoke async code inside its body.
Conclusion
Implementation here can be further optimized for use in CQRS/ES systems however that is outside of the scope of this post. This implementation gives enough flexibility to extend required specific repository with new functionality easily, just by adding custom SQL queries to the repository.


